Evaluation of recommender systems
In this tutorial, we explain how to evaluate recommender systems with implicit feedback by holding out method.
[1]:
from irspack.dataset import MovieLens1MDataManager
from irspack import (
P3alphaRecommender, TopPopRecommender,
rowwise_train_test_split, Evaluator,
df_to_sparse
)
Read the ML1M dataset again.
As in the previous tutorial, we load the rating dataset and construct a sparse matrix.
[2]:
loader = MovieLens1MDataManager()
df = loader.read_interaction()
X, unique_user_ids, unique_movie_ids = df_to_sparse(
df, 'userId', 'movieId'
)
Split scheme 1. Hold-out for all users.
To evaluate the performance of a recommender system trained with implicit feedback, the standard method is to hide some subset of the known user-item interactions as a validation set and see how the recommender ranks these hidden groundtruths:
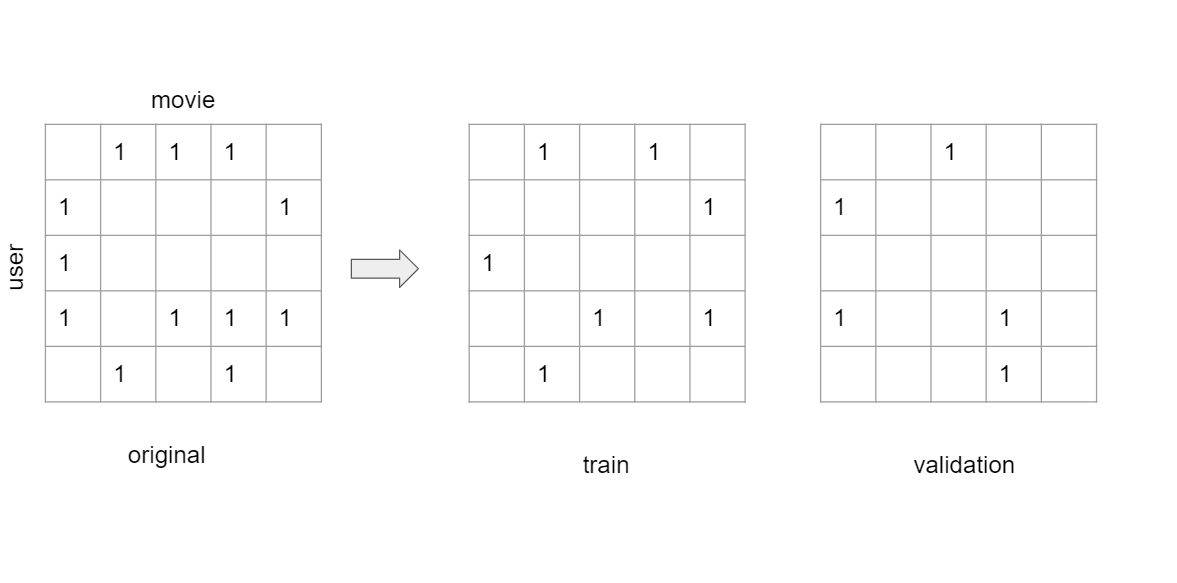
We have prepared a fast implementaion of such a split (with random selection of these subset) in rowwise_train_test_split function:
[3]:
X_train, X_valid = rowwise_train_test_split(X, test_ratio=0.2, random_state=0)
assert X_train.shape == X_valid.shape
They sum back to the original matrix:
[4]:
X - (X_train + X_valid) # 0 stored elements
[4]:
<6040x3706 sparse matrix of type '<class 'numpy.float64'>'
with 0 stored elements in Compressed Sparse Row format>
There is no overlap of non-zero elements:
[5]:
X_train.multiply(X_valid) # Element-wise multiplication yields 0 stored elements
[5]:
<6040x3706 sparse matrix of type '<class 'numpy.float64'>'
with 0 stored elements in Compressed Sparse Row format>
This scheme however has a problem regarding the performance because we have to compute the recommendation score for all the users. So in the next tutorial, we will be using a sub-sampled version of this splitting.
Obtain the evaluation metric
Now we define the Evaluator object, which will measure the performance of various recommender systems based on X_valid (the meaning of offset=0 will be clarified in the next tutorial).
[6]:
evaluator = Evaluator(X_valid, offset=0)
We fit P3alphaRecommender using X_train, and compute its accuracy metrics against X_valid using evaluator.
Internally, evaluator calls the recommender’s get_score_remove_seen method, sorts the score to obtain the rank, and reconciles it with the stored validation interactions.
[7]:
recommender = P3alphaRecommender(X_train, top_k=100)
recommender.learn()
evaluator.get_scores(recommender, cutoffs=[5, 10])
[7]:
OrderedDict([('hit@5', 0.7988410596026491),
('recall@5', 0.09333713653053713),
('ndcg@5', 0.396153990817333),
('map@5', 0.06632471989643292),
('precision@5', 0.37317880794701996),
('gini_index@5', 0.9738255665593293),
('entropy@5', 4.777123828102488),
('appeared_item@5', 536.0),
('hit@10', 0.8925496688741722),
('recall@10', 0.15053594583416965),
('ndcg@10', 0.3662089065311077),
('map@10', 0.08982972949880254),
('precision@10', 0.32049668874172194),
('gini_index@10', 0.961654047669253),
('entropy@10', 5.1898345912683315),
('appeared_item@10', 764.0)])
Comparison with a simple baseline
Now that we have a qualitative way to measure the recommenders’ performance, we can compare the performance of different algorithms.
As a simple baseline, we fit TopPopRecommender, which recommends items with descending order of the popularity in the train set, regardless of the users’ watch event history. (But note that already-seen items by a user will not be commended again).
[8]:
toppop_recommender = TopPopRecommender(X_train)
toppop_recommender.learn()
evaluator.get_scores(toppop_recommender, cutoffs=[5, 10])
[8]:
OrderedDict([('hit@5', 0.5473509933774835),
('recall@5', 0.04097159018092859),
('ndcg@5', 0.21914854330480912),
('map@5', 0.025239375245273265),
('precision@5', 0.20884105960264907),
('gini_index@5', 0.9972226173414867),
('entropy@5', 2.608344593727912),
('appeared_item@5', 42.0),
('hit@10', 0.6637417218543047),
('recall@10', 0.0667908851617647),
('ndcg@10', 0.19939297384808613),
('map@10', 0.033298013667913656),
('precision@10', 0.17811258278145692),
('gini_index@10', 0.9950046639957398),
('entropy@10', 3.1812807131889786),
('appeared_item@10', 69.0)])
So we see that P3alphaRecommender actually exhibits better accuracy scores compared to rather trivial TopPopRecommender.
In the next tutorial, we will optimize the recommender’s performance using the hold-out method.